Google’s Photo App Still Can’t Find Gorillas. And Neither Can Apple’s.
>
Eight years after a controversy over Black people being mislabeled by image analysis software — and despite big advances in computer vision — the tech giants still fear repeating the mistake.
By Nico Grant and Kashmir Hill
When Google released its stand-alone Photos app in May 2015, people were wowed by what it could do: analyze images to label the people, places and things in them, an astounding consumer offering at the time. But a couple of months after the release, a software developer, Jacky Alciné, discovered that Google had labeled photos of him and a friend, who are both Black, as “gorillas,” a term that is particularly offensive because it echoes centuries of racist tropes.
In the ensuing controversy, Google prevented its software from categorizing anything in Photos as gorillas, and it vowed to fix the problem. Eight years later, with significant advances in artificial intelligence, we tested whether Google had resolved the issue, and we looked at comparable tools from its competitors: Apple, Amazon and Microsoft.
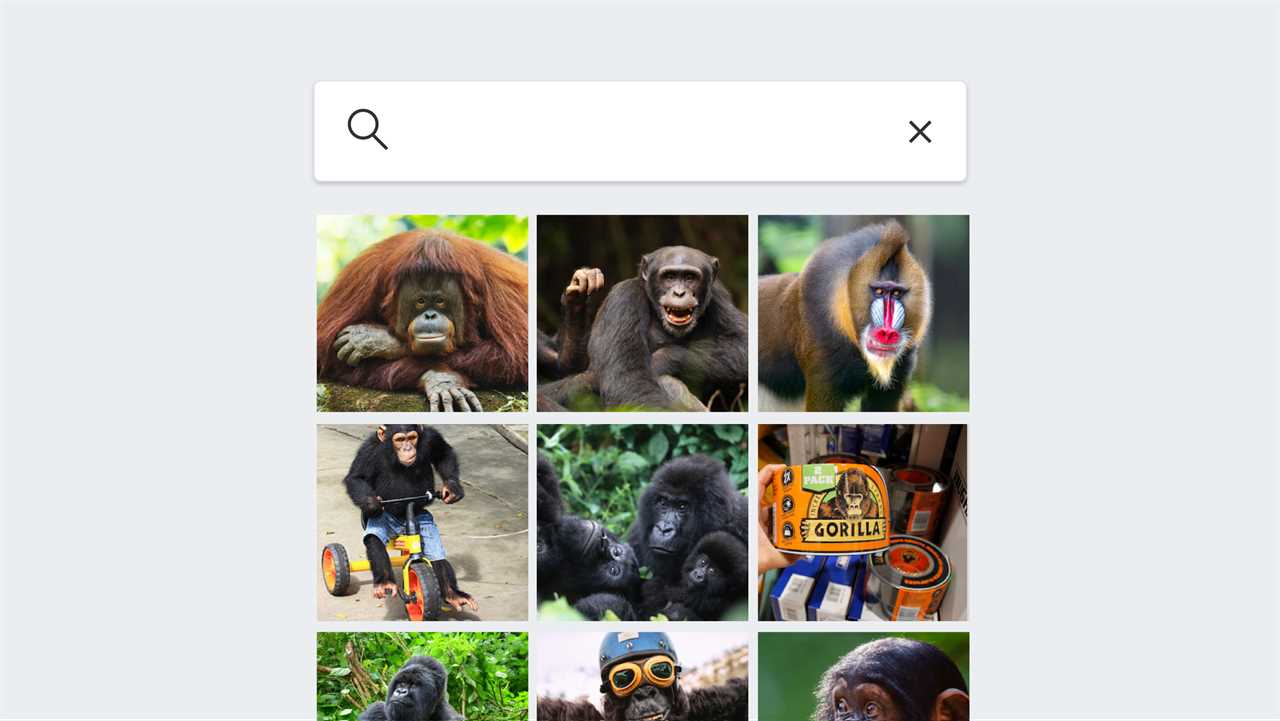
We started with Google Photos. When we searched our collection for cats and kangaroos, we got images that matched our queries. The app performed well in recognizing most other animals.
But when we looked for gorillas, Google Photos failed to find any images. We widened our search to baboons, chimpanzees, orangutans and monkeys, and it still failed even though there were images of all of these primates in our collection.
We then looked at Google’s competitors. We discovered Apple Photos had the same issue: It could accurately find photos of particular animals, except for most primates. We did get results for gorilla, but only when the text appeared in a photo, such as an image of Gorilla Tape.
The photo search in Microsoft OneDrive drew a blank for every animal we tried. Amazon Photos showed results for all searches, but it was over-inclusive. When we searched for gorillas, the app showed a menagerie of primates, and repeated that pattern for other animals.





